Основные понятия
Чтобы лучше понять устройство StatsHouse, познакомьтесь с основными понятиями:
- Агрегация
- Кардинальность
- Семплирование
Агрегация
StatsHouse агрегирует, то есть "схлопывает", измерения с одинаковыми наборами тегов — как в пределах временного интервала, так и между хостами.
Агрегат
Агрегат — это результат агрегации. Это минимальный набор описательных статистик: count, sum, min, max. На основе них StatsHouse при необходимости восстанавливает остальные статистики. Например, вот как выглядит секундный агрегат:
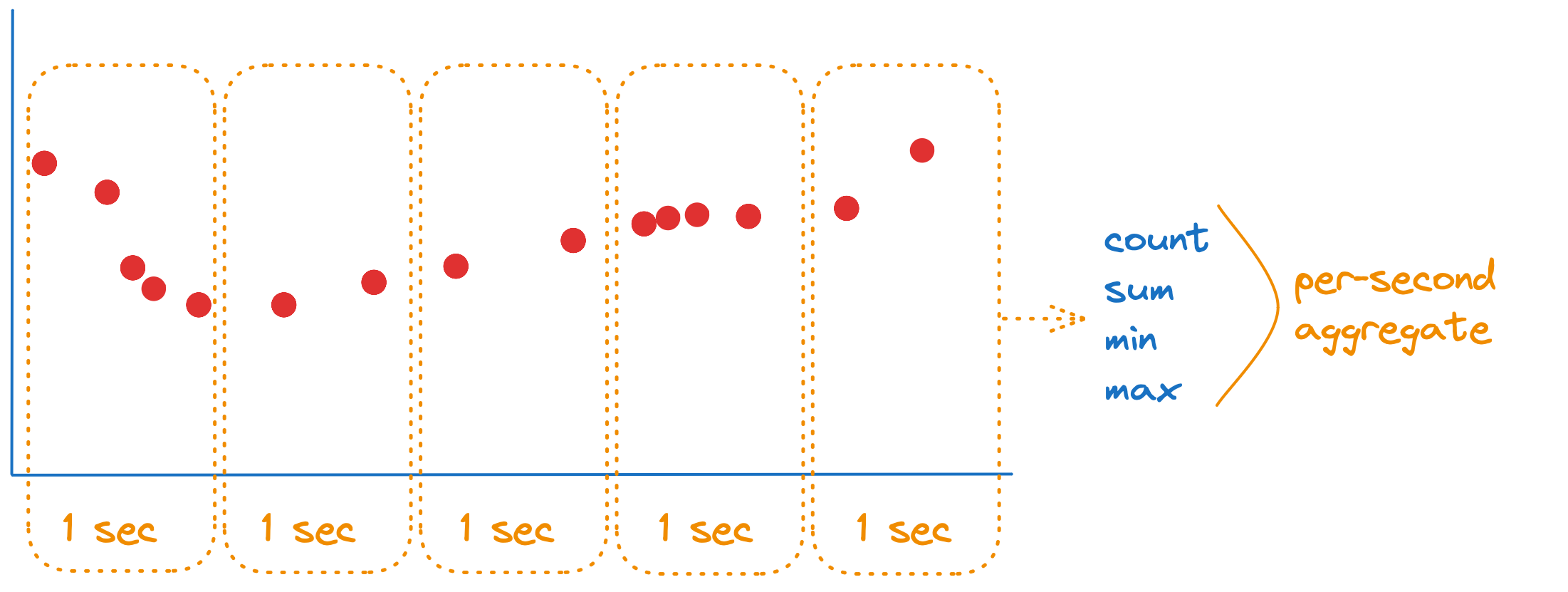
StatsHouse не хранит точное значение метрики за каждый момент времени. Вместо этого в системе хранятся агрегаты, относящиеся к временным интервалам (см. минимальный доступный интервал агрегации).
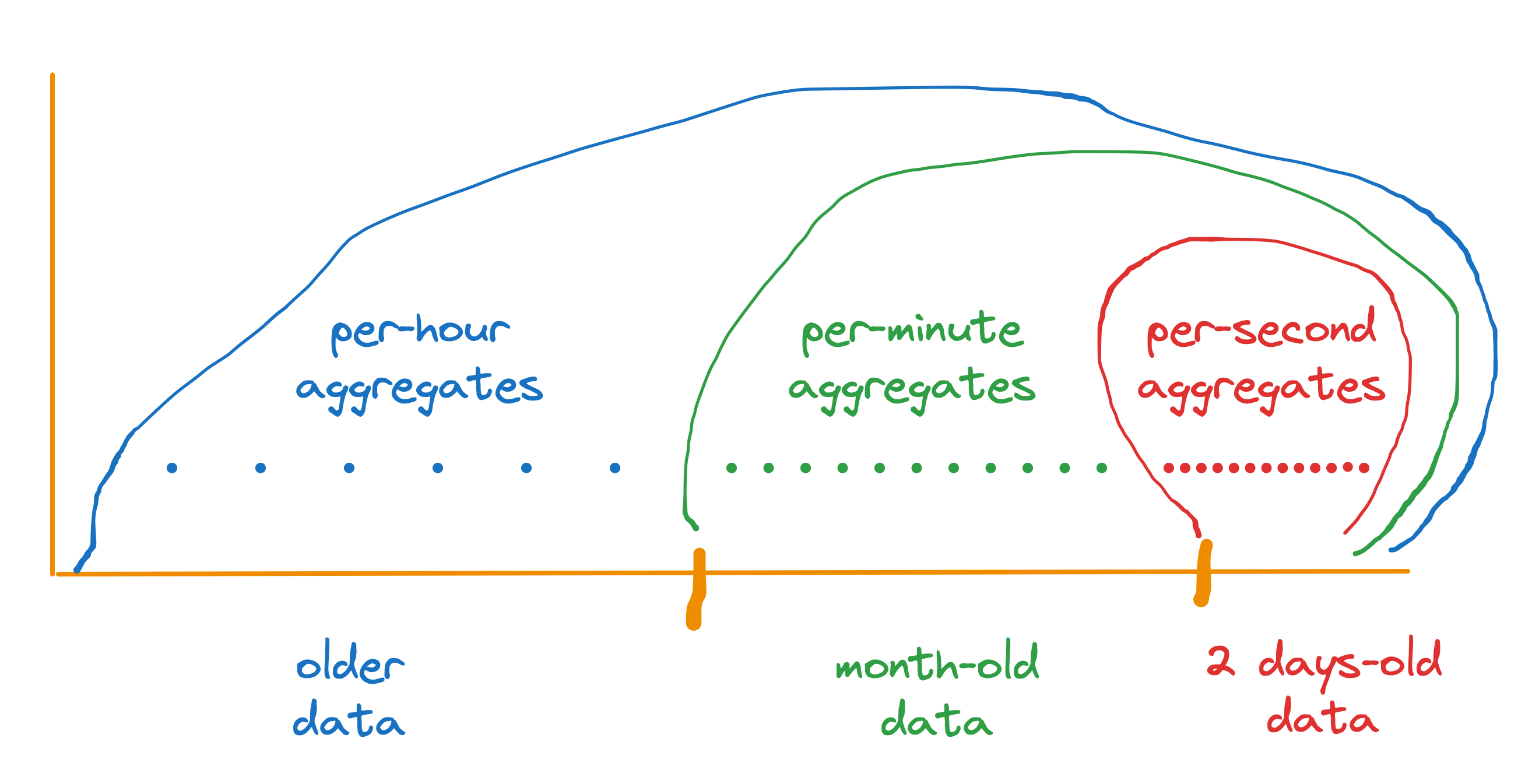
StatsHouse вставляет агрегированные данные в базу данных ClickHouse, а именно в секундную таблицу. Посекундных данных очень много, поэтому с течением времени StatsHouse уменьшает их разрешение, чтобы хранить меньше. StatsHouse агрегирует данные ещё сильнее — в пределах каждой минуты — и вставляет их в минутную таблицу. Затем данные агрегируются в пределах каждого часа.
Минимальный доступный интервал агрегации
То, какой агрегат доступен в данный момент времени, зависит от "�возраста" данных:
- данные, агрегированные по секундам, хранятся в течение первых двух дней,
- данные, агрегированные по минутам, хранятся в течение месяца,
- данные, агрегированные по часам, хранятся как угодно долго (или до тех пор, пока их не удалят вручную).
Представьте себе гипотетический продукт. Для него нам нужно получить количество принятых пакетов в секунду. Пакеты могут иметь различные
- форматы:
TL,JSON; - статусы: "правильный" (
ok) или "неправильный" (error_too_short,error_too_longи т.д.).
Когда пользовательский код получает пакет, он отправляет событие в StatsHouse, а именно в агент. Например, пусть это событие имеет формат JSON и статус "правильно":
{"metrics":[ {"name": "toy_packets_count",
"tags":{"format": "JSON", "status": "ok"},
"counter": 1}] }
Форматы и статусы пакетов могут различаться:
{"metrics":[ {"name": "toy_packets_count",
"tags":{"format": "TL", "status": "error_too_short"},
"counter": 1} ]}
Представим событие в виде ряда в обычной базе данных. При посекундной агрегации мы получим таблицу, которая показана ниже. Для каждой полученной комбинации значений тегов в ней появится ряд с соответствующим счётчиком:
| timestamp | metric | format | status | counter |
|---|---|---|---|---|
| 13:45:05 | toy_packets_count | JSON | ok | 100 |
| 13:45:05 | toy_packets_count | TL | ok | 200 |
| 13:45:05 | toy_packets_count | TL | error_too_short | 5 |
Количество рядов в такой таблице - это кардинальность метрики.
Разрешение
Максимальное разрешение, с которым можно отобразить данные на графике, зависит от того, какие агрегаты доступны в данные момент: пос�екундные данные можно получить в течение двух последних дней, поминутные данные доступны за последний месяц, часовые данные — за любой период.
Если для вас не так важно получать данные с максимальным разрешением, однако важно минимизировать семплирование, уменьшите разрешение метрики.
Например, вы можете выбрать такое разрешение, чтобы агент отправлял данные раз в пять секунд, а не раз в секунду. StatsHouse будет отправлять данные в пять раз реже и выделять метрике в пять раз больше рядов.
Задержка увеличится на десять секунд:
- StatsHouse будет собирать данные в течение пяти секунд,
- затем шардировать данные на пять частей,
- и отправлять данные в течение следующих пяти секунд — по одному шарду в секунду.
Такой способ отправки данных обеспечивает справедливое распределение канала для метрик с разным разрешением.
Кардинальность
Кардинальность - это количество уникальных комбинаций значений тегов, которые вы отправляете для метрики.
В приведённом выше примере кардинальность метрики для текущей секунды равна трём, поскольку у нас есть три комбинации значений тегов.
Объём вставляемых данных не зависит от количества событий. Он зависит от количества уникальных комбинаций значений тегов. StatsHouse "схлопывает" ряды с одинаковыми комбинациями значений тегов и суммирует счётчики.
StatsHouse собирает данные со многих хостов (агентов) одновременно. После сбора и агрегирования данных в пределах секунды он отправляет данные на агрегаторы.
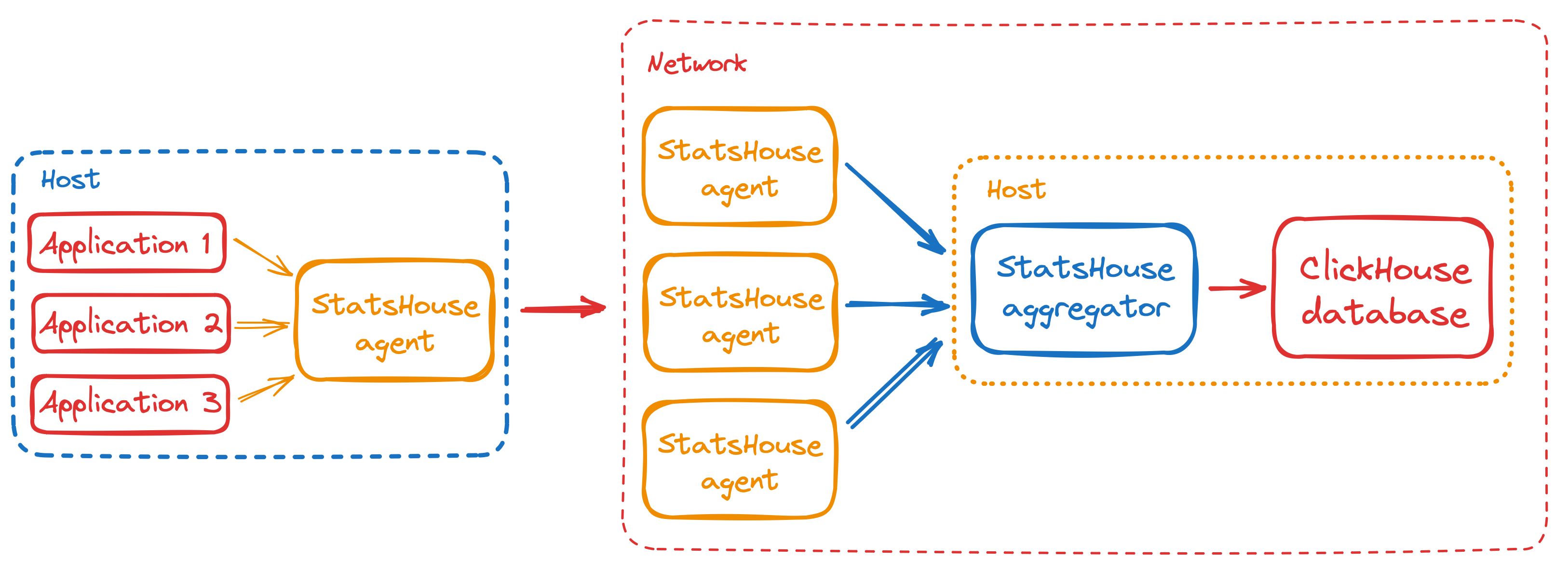
Для нашей гипотетической метрики в результате агрегации между хостами в пределах секунды мы получим следующее:
| timestamp | metric | format | status | counter |
|---|---|---|---|---|
| 13:45:05 | toy_packets_count | JSON | ok | 1100 |
| 13:45:05 | toy_packets_count | JSON | error_too_short | 40 |
| 13:45:05 | toy_packets_count | JSON | error_too_long | 20 |
| 13:45:05 | toy_packets_count | TL | ok | 30 |
| 13:45:05 | toy_packets_count | TL | error_too_short | 2400 |
| 13:45:05 | toy_packets_count | msgpack | ok | 1 |
Кардинальность может увеличиваться из-за агрегации между хостами: комбинации значений тегов могут быть разными для разных хостов. В приведённом примере общая кардинальность для текущей секунды составляет шесть.
Общая часовая кардинальность для метрики определяет, сколько рядов для метрики может храниться в базе данных в течение длительного времени.
Чтобы извлечь данные из базы, нам придётся перебирать ряды для выбранного временного интервала. Именно кардинальность определяет количество этих рядов и время, которое придётся потра�тить на такой перебор.
Семплирование
У StatsHouse есть два узких места:
- отправка данных от агентов к агрегаторам,
- вставка данных в базу ClickHouse.
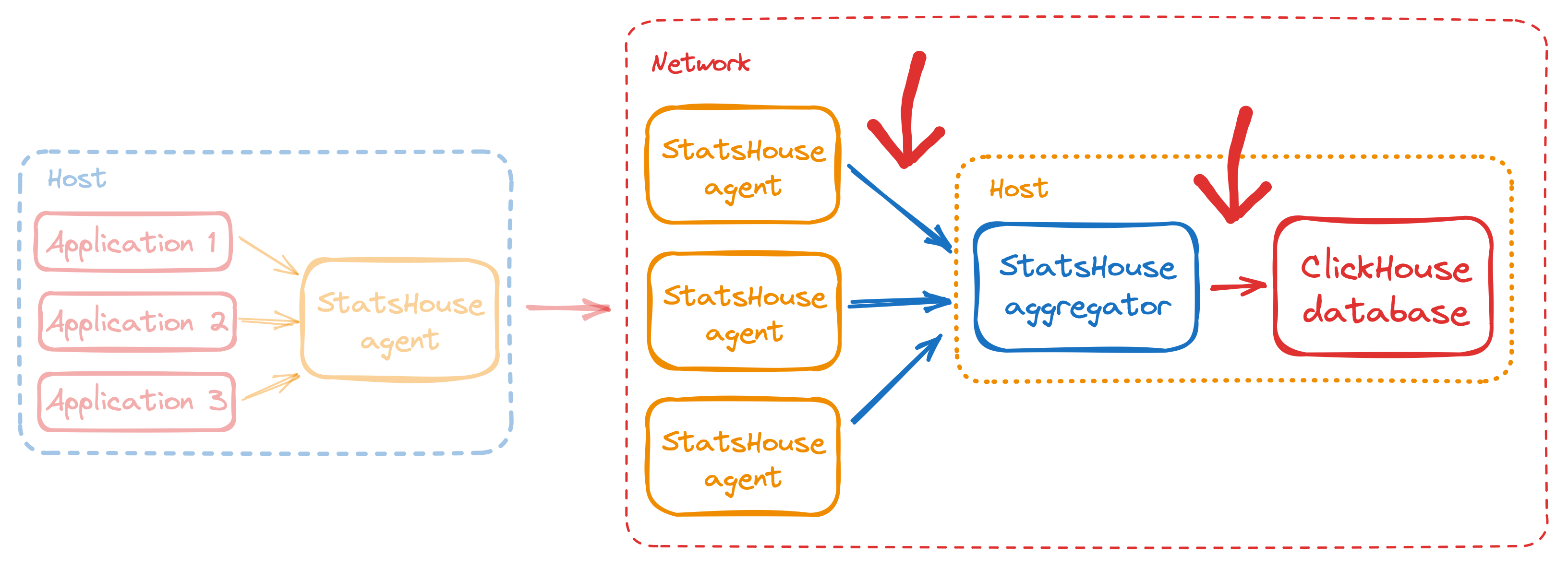
Если объём отправленных или вставляемых данных (количество рядов) превышает возможности агрегатора или базы данных, может возникать задержка. В принципе, эта задержка может увеличиваться бесконечно, а может и исчезнуть, когда объём данных уменьшится. Чтобы обеспечить минимальную задержку, StatsHouse семплирует данные.
Семплирование означает, что StatsHouse выбрасывает часть рядов, чтобы уменьшить общий объём вставляемых данных. Чтобы сохранить значения агрегатов и статистик, StatsHouse домножает суммы и счётчики в оставшихся рядах на коэффициент семплирования.
Предположим, что за секунду собраны три ряда данных, причём все они принадлежат одной метрике:
| timestamp | metric | format | status | counter |
|---|---|---|---|---|
| 13:45:05 | toy_packets_count | JSON | ok | 100 |
| 13:45:05 | toy_packets_count | TL | ok | 200 |
| 13:45:05 | toy_packets_count | TL | error_too_short | 5 |
Предположим также, что ширина канала позволяет нам отправить агрегатору только два ряда. StatsHouse выберет
коэффициент семплирования, равный 1,5, затем перемешает ряды случайным образом и отправит только первые два,
домноженные на 1,5.
Отправленные данные будут выглядеть следующим образом:
| timestamp | metric | format | status | counter |
|---|---|---|---|---|
| 13:45:05 | toy_packets_count | TL | ok | 300 |
| 13:45:05 | toy_packets_count | JSON | ok | 150 |
или так:
| timestamp | metric | format | status | counter |
|---|---|---|---|---|
| 13:45:05 | toy_packets_count | TL | ok | 300 |
| 13:45:05 | toy_packets_count | TL | error_too_short | 7.5 |
или вот так:
| timestamp | metric | format | status | counter |
|---|---|---|---|---|
| 13:45:05 | toy_packets_count | TL | error_too_short | 7.5 |
| 13:45:05 | toy_packets_count | JSON | ok | 150 |
Если каждый агент семплирует данные таким образом, он выбрасывает часть рядов. Однако при агрегации данных между агентами значения счётчиков каждого ряда будут близки к исходным (как будто данные вообще не семплировались). Чем больше агентов участвует в агрегации, тем точнее получаются счётчики.
То же самое произойдёт при агрегации рядов за 60 секунд в один минутный ряд, и, далее, в часовой. Все средние значения агрегатов сохранятся, но к ним добавится высокочастотный шум.

Мы настоятельно рекомендуем следить за тем, чтобы кардинальность метрик была минимальной.
Один и тот же алгоритм применяется как перед отправкой данных на агрегатор, так и перед вставкой в базу данных.
Коэффициент семплирования
Коэффициент семплирования = объём отправляемых данных (ряды) / бюджет (ряды)
Например:
вы отправляете 100 рядов в секунду, а вставить в агрегатор можно только 20 рядов.
- Коэффициент семплирования будет равен 5.
- StatsHouse уменьшит объём отправляемых данных в 5 раз: 1/5 рядов оставит, а остальные 4/5 выбросит.
- Счётчики и значения в оставшихся рядах будут домножены на 5.
Как заранее узнать, какое будет семплирование у ваших метрик?
Заранее вычислить, как будет семплироваться метрика, не удастся. Почему?
Оба значения (объём отправляемых данных и бюджет) изменчивы:
- Бюджет — величина относительная. Это вес, а не фиксированное значение в байтах.
- Объём отправляемых данных может существенно меняться.
Поэтому лучше начать отправлять метрики в StatsHouse и опытным путём выяснить, какой коэффициент семплирования будет получаться.
Где посмотреть коэффициент семплирования?
Над каждым графиком отображаются ссылки на две метаметрики:

__src_sampling_factor — информация о коэффициенте семплирования на уровне агента (source),
__agg_sampling_factor — информация о коэффициенте семплирования на уровне агрегатора (aggregator).
Узнайте больше о метаметрике Sampling.
Как понимать коэффициент семплирования?
Как понимать числа, которые вы видите на метриках семплирования?
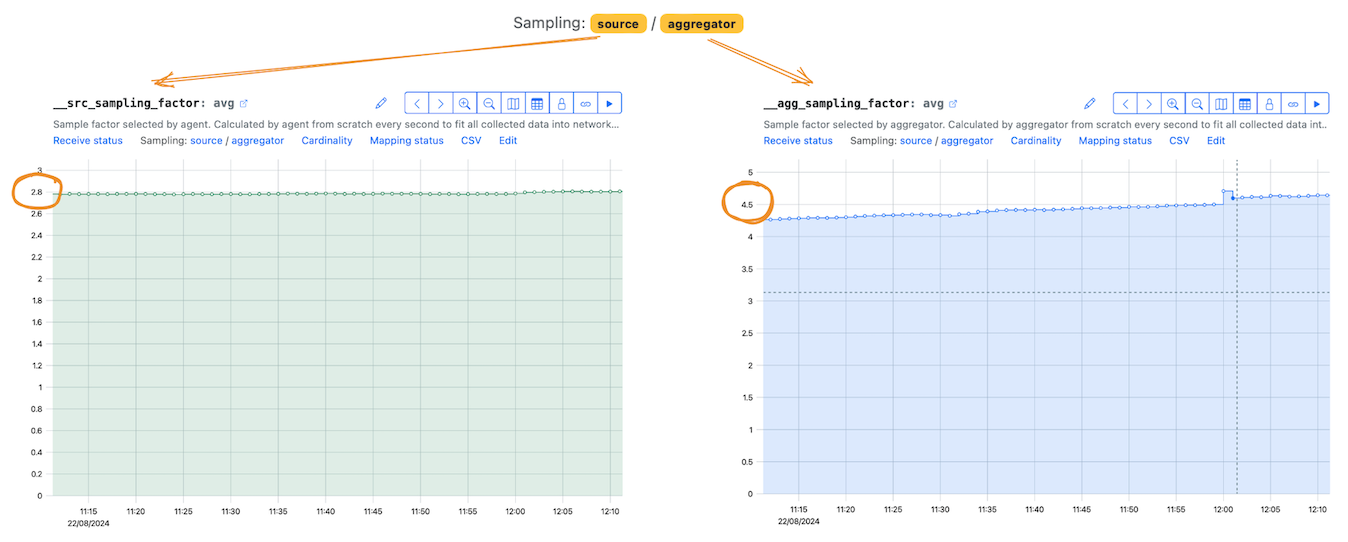
Это НЕ процент выбрасываемых рядов.
Числа на графике — коэффициенты семплирования (sampling factor, SF). Они показывают, во сколько раз уменьшился объём отправленных данных. И, соответственно, на какое число домножаются счётчики и значения в оставшихся рядах.
SF = 2 — остаётся ровно половина рядов. Объём отправленных данных уменьшен в два раза.
SF = 3 — остаётся 1/3 рядов, то есть в три раза меньше, чем отправляли.
SF = 1,5 — остаётся 2/3 рядов. Объём отправленных данных уменьшен в полтора раза.
SF = 100 означает, что остаётся один ряд из 100. Объём отправленных данных уменьшен в сто раз.
Чем больше SF, тем меньше данных оставляем.
Нецелые коэффициенты семплирования
Системе иногда приходится выбирать нецелые коэффициенты семплирования, чтобы сохранить значения агрегатов и статистик. Из-за этого счётчики могут принимать нецелые значения, хотя каждый счётчик по сути является целым числом.
В StatsHouse счётчики по умолчанию являются числами с плавающей точкой.
Для конкретной метрики можно установить настройку, которая позволит округлять коэффициенты семплирования случайным
образом. Если коэффициент семплирования равен 1,1, он будет округлен до 1 девять раз из десяти, а до
2 только один раз.
Справедливое распределение ресурсов
Теперь предположим, что у нас есть несколько метрик, и они используют один и тот же канал заданной ширины. В идеале метрики не должны влиять друг на друга. Если метрика начинает генерировать гораздо больше рядов, чем остальные, она должна получить более высокий коэффициент семплирования, чтобы другие метрики не пострадали.
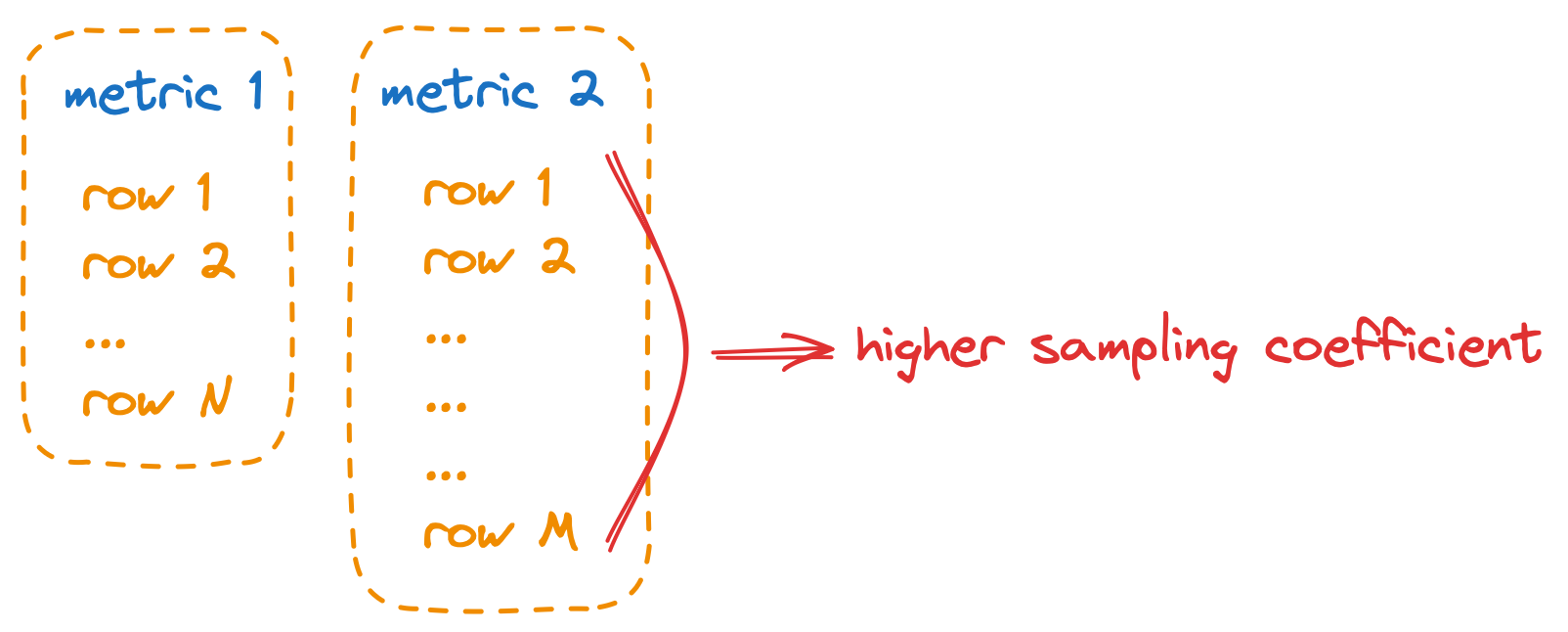
Алгоритм работает таким образом:
- StatsHouse сортирует все метрики в порядке возрастания по количеству занятых байтов. Затем обращается к ним по очереди.
- StatsHouse вычисляет количество байтов, которое нужно выделить каждой метрике. Оставшийся бюджет распределяется между остальными метриками.
- Если метрика не расходует свой бюджет, её данные вообще не семплируются.
- Если метрика превышает свой бюджет, StatsHouse семплирует данные таким образом, чтобы они укладывались в бюджет: для метрики с 2000 рядов и бюджетом в 500 рядов будет выбран коэффициент семплирования, равный четырём.
- StatsHouse уменьшает оставшуюся часть бюджета на количество потраченных байтов.
Количество занятых байтов зависит от типа метрики и количества значений тегов. Метрики типа counter требуют меньше места, чем метрики типа value.
Бывает, что одни метрики важнее других. Администраторы StatsHouse могут установить веса для конкретных метрик. Метрика с весом 2 получает в два раза более широкий канал, чем канал для метрики с весом 1.
Семплирование "китов"
Описанный выше алгоритм хорошо работает, когда исходные счётчики рядов близки друг к другу. Часто в метрике есть один или несколько доминирующих рядов — "китов". Например, если мы успешно обрабатываем 1000 пакетов в секунду, но при этом получаем по одной ошибке каждого типа, то первый ряд ("ok") становится "китом":
| timestamp | metric | format | status | counter |
|---|---|---|---|---|
| 13:45:05 | toy_packets_count | JSON | ok | 1000 семплироваться |
| 13:45:05 | toy_packets_count | TL | error_too_short | 1 |
| 13:45:05 | toy_packets_count | TL | error_too_long | 1 |
| 13:45:05 | toy_packets_count | TL | error_too_bad | 1 |
| 13:45:05 | toy_packets_count | TL | error_too_good | 1 |
Когда мы отображаем сумму счётчиков на графике, мы получаем гладкий график со значением 1004.
Представьте, что бюджет позволяет вставить только четыре ряда из пяти. Мы будем выбрасывать по одному ряду каждую секунду:
- для четырех секунд из пяти зна�чение будет
1003 * (5 / 4) ~ 1203, - для одной секунды из пяти значение будет
4 * (5 / 4) = 5.
В среднем эти значения выглядят правильно: если их просуммировать, то получится 1004. Но график будет расположен
гораздо выше среднего значения — в районе 1200 — и будет иметь провалы до 0.
При семплировании "китов" (доминирующих рядов) StatsHouse делит бюджет надвое:
- Первую половину бюджета (два ряда в данном примере) расходует на ряды с максимальным значением счётчика. Эти ряды не семплируются.
- Вторая половина бюджета тратится на случайные из оставшихся рядов. Они будут семплироваться пропорционально сильнее.
В нашем примере StatsHouse вставит ряд со счётчиком, равным 1000, как есть, т.е. не будет семплировать этот ряд.
Мы получим график со средним значением 1004.
Если вам важ�но отлавливать (никогда не выбрасывать!) пиковые значения в данных, может показаться, что семплирование "китов" вас защитит.
Но это, увы, не так. Алгоритм семплирования "китов" позволяет особым образом сохранять информацию о сигнале, чтобы форма графика (сигнала) сильно не "дрожала". Алгоритм НЕ предназначен для того, чтобы гарантировать "невыбрасывание" рядов с пиковыми значений.
Почему?!
В реальности алгоритмы, связанные с коэффициентом семплирования, работают вероятностно. "Подбрасывается кубик" с заданной вероятностью: выбрасываем ряд или нет. В приведённом ниже примере показан примерный физический смысл происходящего.
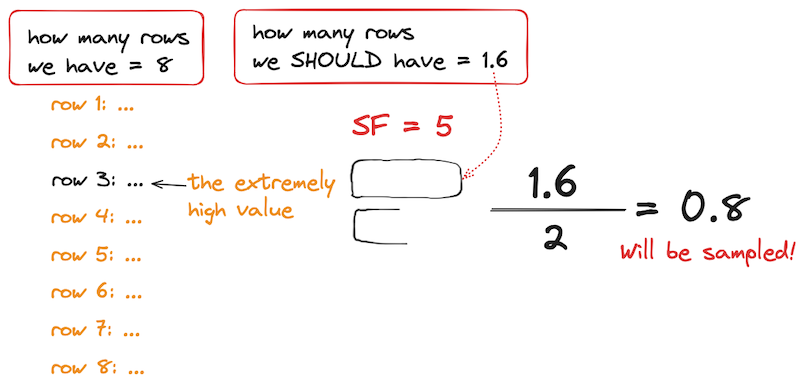
Представим себе ситуацию:
-
мы хотим отправить 8 рядов данных
-
бюджет требует от нас уменьшить объём отправляемых данных в пять раз: SF = 5
-
один из рядов содержит пиковые значения
→ При обычном семплировании нам хватило бы бюджета, чтобы вставить 1,6 ряда (8/5=1,6). Конечно, вставится всего один ряд. Может вставиться как ряд с пиковым значением, так и любой другой.
→ Зная коэффициент семплировани�я, мы должны понять, можно ли применить алгоритм семплирования "китов".
Количество рядов, которые нам разрешено записать, нужно разделить надвое:
1,6 / 2 = 0,8
Результат деления оказался меньше единицы. Это значит, что мы не можем выделить половину бюджета для "китов". Округлить его в большую сторону нельзя — иначе отправим больше байтов, чем разрешено. Придётся отказаться от алгоритма с "китами" и, возможно, выбросить пиковое значение!..
Исключить семплирование нельзя, но вы можете минимизировать его вероятность.
Пользовательское семплирование
Лучше, когда семплированием данных занимается StatsHouse. Однако �вам может быть нужно семплировать данные перед отправкой в StatsHouse самостоятельно, чтобы контролировать объём занятой памяти.
В таком случае вы можете явно указать counter для value-метрики:
`{"metrics":[{"name":"my_metric","tags":{},"counter":6, "value":[1, 2, 3]}]}`
Такой вариант отправки означает, что количество событий равно 6, а значения семплируются так, как если бы value
исходно было таким: [1, 1, 2, 2, 3, 3].
Бюджетирование на уровне т�егов ("Fair key tags")
Бюджетирование на уровне тегов ("Fair key tags") предназначено для коммунальных метрик — таких, в которые отправляют данные сразу несколько сервисов. Опция "Fair key tags" позволяет поровну распределять бюджет метрики — в соответствии со значениями тега, например между разными сервисами.
Если НЕ включать бюджетирование на уровне тегов
Представьте, что в вашу метрику отправляют данные два сервиса: Service A и Service B.
Идентификаторы этих сервисов записываются в тег service_id, так что данные от Service A можно отличить от
данных, приходящих из Service B.
Допустим,
- Service A присылает 99 событий в секунду.
- Service B присылает одно событие в секунду.
В этом случае среди 100 рядов, полученных от метрики и хранящихся в базе данных,
- 99 принадлежат первому сервису (Service A),
- и только один ряд принадлежит второму сервису (Service B).
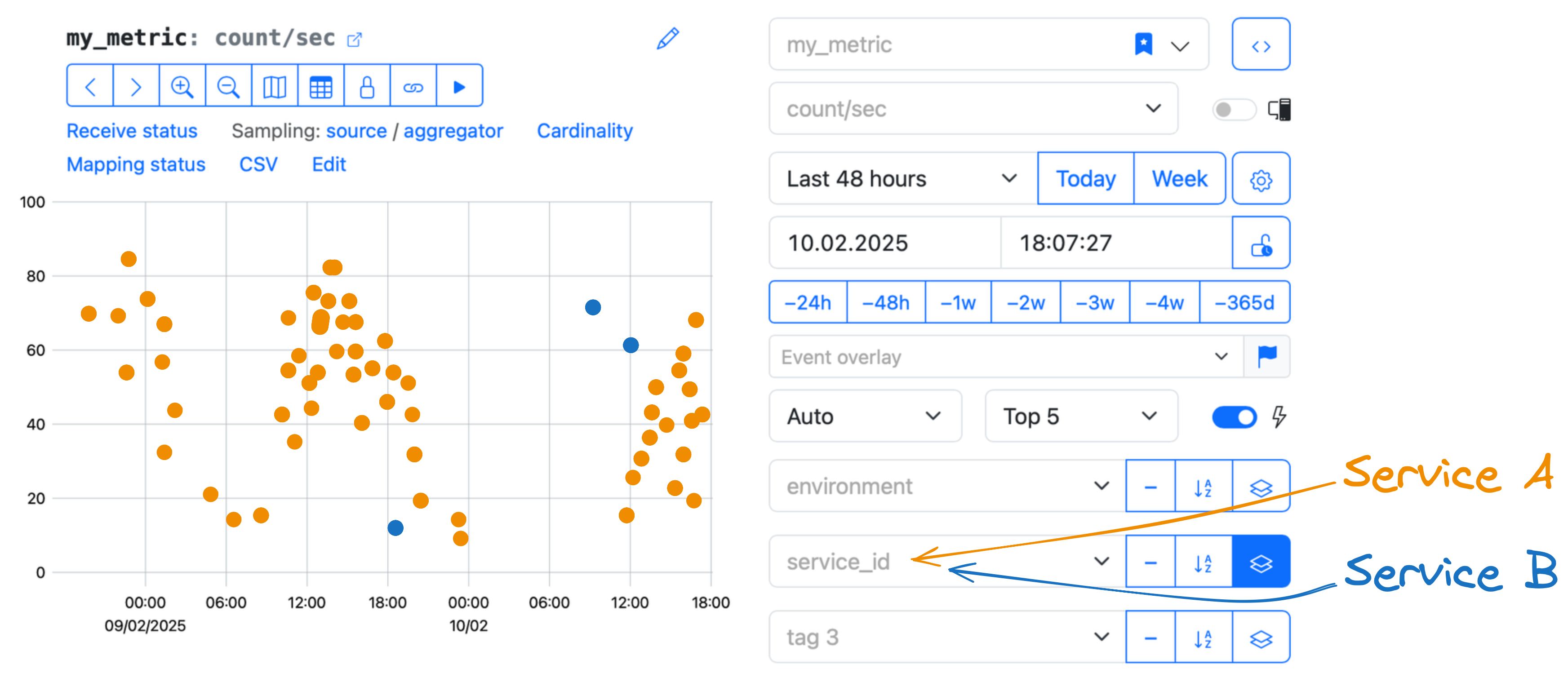
В рамках метрики данные от обоих сервисов семплируются в равной степени. Из-за этого ряды от Service B попадают в базу данных реже, чем ряды от Service A.
Если коэффициент семплирования (SF) равен десяти, значит, в базе остаётся лишь один ряд из десяти.
- Для Service A: девять рядов попадут в базу данных с вероятностью 100%, ещё один ряд (десятый) — с вероятностью 90%;
- Для Service B: только один ряд попадёт в базу данных — с вероятностью 10%.
Если включить бюджетирование на уровне тегов
Тег service_id можно выбрать в качестве "ключа с честным семплированием", чтобы поделить бюджет метрики между сервисами поровну.
Узнайте больше о том, как включить опцию "Fair key tags" для конкретного тега. Бюджет метрики распределится между двумя сервисами поровну:
- у редких событий из Service B появится больше шансов попасть на график StatsHouse;
- Service A, который генерирует больше событий, получит меньший бюджет.