TLDR
Главная особенность StatsHouse — способность "переваривать" сколько угодно данных и отображать их в режиме реального времени. Это возможно благодаря агрегации и семплированию: данные приходится сжимать и (иногда) выбрасывать.
Избавиться от семплирования в общем случае нельзя (и чаще всего это не нужно).
Чтобы понять, подходит ли вам StatsHouse, узнайте, какие механизмы и понятия лежат в основе этой системы. Они описаны ниже — в двух словах и картинках:
Агрегация
Узнайте больше об агрегации. Здесь приводится лишь краткое объяснение.
StatsHouse "схлопывает" ряды данных с одинаковыми значениями тегов. Счётчики при этом суммируются.

StatsHouse НЕ хранит точное значение метрики за каждый момент времени. Хранится только общая статистика (агрегат = count, sum, min, max) за временной интервал.
Максимальное разрешение — одна секунда. Данные с таким разрешением доступны в течение двух дней, затем разрешение уменьшается (до минут и часов).
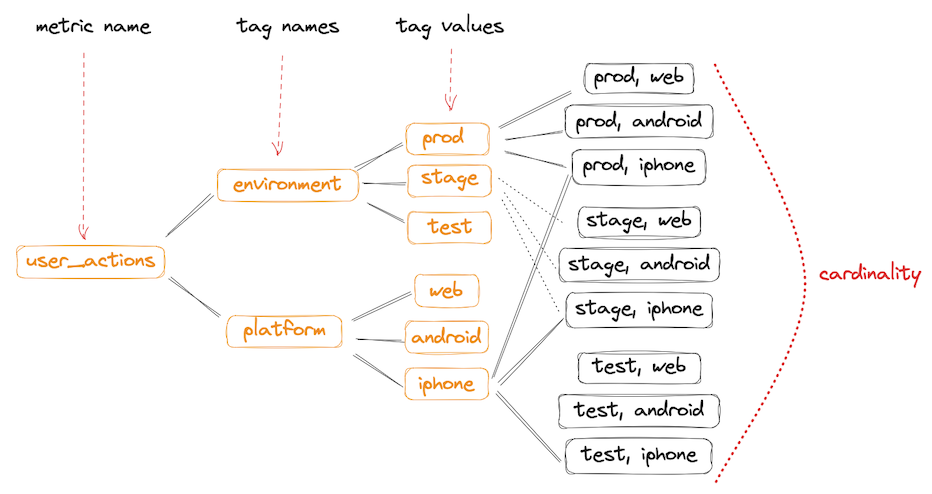
Кардинальность
Узнайте больше о кардинальности. Здесь приводится лишь краткое объяснение.
Данные с высокой кардинальностью — это данные, в которых много разных значений тегов. Они плохо сжимаются, занимают большой объём, и их приходится семплировать.
Данные с низкой кардинальностью хорошо агрегируются (сжимаются), и обычно их не приходится семплировать.
Семплирование
Узнайте больше о семплировании. Здесь приводится лишь краткое объяснение.
При слишком высоких нагрузках StatsHouse выбрасывает случайные ряды данных. Суммы и счётчики в оставшихся рядах домножаются на коэффициент семплирования так, чтобы сохранялись средние значения.
В большинстве случаев семплирование не мешает пользователям и защищает систему от перегрузки.
Гарантировать отсутствие семплирования нельзя!


Как минимизировать семплирование?
Семплирование включается, когда вы отправляете в StatsHouse больше рядов данных, чем вам разрешено. Вы можете либо уменьшить объём отправляемых данных (1–3), либо увеличить бюджет (4).
- Минимизируйте кардинальность — количество значений тегов. Количество самих тегов не так важно, их и так не очень много. Важнее то, сколько разных значений может принимать каждый тег.
Не используйте userID или hostname в качестве значения тега. Используйте в качестве значений более крупные
категории.
Делите пользователей не по персональному идентификатору, а по региону, платформе и т.п.
Хосты можно делить не по имени, а по датацентру, кластеру и т.п.
- Учтите тип метрики — от него зависит объём отправляемых данных:
- метрики типа counter занимают меньший объём по сравнению с метриками типа value;
- включение перцентилей увеличивает объём данных — это может привести к усилению семплирования.
- Уменьшите разрешение метрики. Узнайте, как это сделать.
- Увеличьте бюджет. Настроить бюджет для отдельных метрик (а также групп и неймспейсов) могут администраторы StatsHouse. Не злоупотребляйте этой возможностью.
Чтобы поровну распределить бюджет между сервисами, которые отправляют данные в одну и ту же метрику, можно включить опцию "Fair key tags". Узнайте больше о бюджетировании на уровне тегов.
Что НЕ поможет минимизировать семплирование?
Если вы отправляете много рядов и начинаете писать меньше значений в те же ряды, ситуация с семплированием не изменится.
Например, вы можете отправлять два ряда данных: [a=1, b=2] и [a=1, b=3] — ряды разные потому, что в них
сочетаются разные значения тегов. Не слишком важно, отправляете ли вы в эти два ряда всего 4 значения или 1
миллион (это справедливо для типов counter и value). Но если метрика вместо двух рядов генерирует 2 миллиона
рядов в секунду, такие данные скорее всего будут семплироваться.
Почему нельзя гарантировать отсутствие семплирования?
Избавиться от семплирования в общем случае нельзя. StatsHouse предназначен для работы в режиме коммунального кластера: ресурс справедливо распределяется между пользователями.
Выделенный пользователю ресурс представляет собой фиксированную долю от общего объёма ресурсов. Если в организации ре�сурс уже распределён между пользователями и новые не добавляются, то пользователи не будут друг другу мешать, и даже можно эмпирическим способом минимизировать семплирование.
При масштабировании (добавлении новых пользователей) фактический бюджет в байтах может уменьшаться. В реальной организации эта проблема решается путем увеличения общего бюджета, т.е. физического расширения кластера.